




8章 Rinda
Rindaは分散処理システムLindaのtuple spaceのRubyによる実装です Lindaではタプルとタプル空間の二つの概念があります。 タスクはタプルをタプル空間へ書き込んだり、 タプル空間からタプルを取り出したりすることで通信を行ないます。 Lindaのモデルはきわめて単純ですが、 複雑なプロセス間通信を容易に記述することができます。
この章ではLindaのRubyによる実装であるRindaについて紹介し、 Rindaを利用したアプリケーションを紹介します。
8.1 LindaとRinda
8.1.1 Linda
並列プログラミングには、計算・処理を記述する計算言語と 処理を協調させる協調言語が必要と言われます。 個別に書かれたプログラムの集まりを統一されたプログラムに組み立てるための 「糊」となるのが協調言語です。 Lindaはこの協調言語の一つで、D.Gelernterを中心に開発されました。 Lindaではタプルと呼ばれるデータと、 タプルスペースと呼ばれる分散共有メモリに対する6種類の操作を用いて 並列化を実現します。 Lindaは既存の言語、例えばCやFortranに対する拡張として提供されます。 *1 異なる計算言語、OS間であっても協調することができます。
Lindaには次の6つの操作があります。
- out - タプルをタプルスペースに置く。
- in - パターンにマッチしたタプルをタプルスペースから取り出す。 マッチするタプルがなければブロックする。
- rd - パターンにマッチしたタプルをタプルスペースからコピーする. マッチするタプルがなければブロックする。
- inp - inのノンブロック版。 マッチするタプルがなければエラーを返す。
- rdp - rdのノンブロック版 マッチするタプルがなければエラーを返す。
- eval - 新たなプロセスを起動して評価する
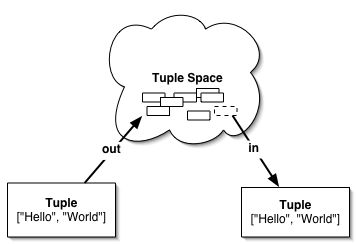
図8.1 Lindaのout操作とin操作のイメージ。
8.1.2 Rinda
RindaはLindaをRubyのスレッド間、あるいはプロセス間を 協調させるためのクラスライブラリです。 Lindaが言語に依存しないのに対し、RindaはRubyに依存しています。 Rubyが稼働していれば、異なるOS間のプロセスを協調することが可能である点は Lindaと同様です。
RindaにはLindaの重要な概念であるタプルとタプルスペース、in操作、out操作を 実装しましたが、新たなプロセスを起動するeval操作はよいアイデアがなく 用意することができませんでした。 また、inやoutはそれぞれtake、writeに改名されています。 これらの名前は、やはりRindaと同様にLindaをJava上の クラスライブラリとして実装したJavaSpacesのメソッド名に近い名前です。
RindaとLindaの違いはこのくらいです。 おそらくLindaの応用例の多くをRindaで試すことができるでしょう。 Lindaのすばらしい協調のアイデアをRindaで体験してみてください。
8.2 Rindaの基本操作
8.2.1 TupleSpaceの生成
Lindaのタプルスペースは6つの操作に隠されて陽に見えませんが、 RindaのタプルスペースはRinda::TupleSpaceというクラスとして実装されています。
以下に'druby://:12345'というURIでタプルスペースを提供する dRubyのスクリプトを示します。 dRubyではホスト名を自動的に補うので、このサービスは 'druby://ホスト名:12345'というURIで提供されます。 同じマシンからこのサービスを利用する場合には 'druby://localhost:12345'と指定することもできます。
List 8.1 ts01.rb
# ts01.rb
require 'rinda/tuplespace'
$ts = Rinda::TupleSpace.new
DRb.start_service('druby://:12345', $ts)
puts DRb.uri
DRb.thread.join
Rinda::TupleSpaceを使用するには'rinda/tuplespace'をrequireします。
TupleSpace.new(timeout=60)-
TupleSpaceを生成します。引数にkeeperスレッドを起動する間隔を秒で 指定します。keeperスレッドはタプルスペースに残された期限切れのタプルや 有効期限の切れた操作の要求を見つけて削除したり例外を発生させたりします。 デフォルトは60秒です。
Rinda::TupleSpaceはQueueやMutexなどのようにスレッド間の同期に 使えるだけでなく、やはりdRubyで公開することが可能です。
続いてTupleSpaceの基本機能を見ていきます。
8.2.2 タプルとwrite、take
Rindaでは複数の値を並べたArrayをタプルと呼びます。 タプルの中には任意のオブジェクトを入れることができます。 通常のオブジェクトだけでなく、 ThreadやProcまでも入れることができますが、 ちょっと実用にはならないかもしれません。
Arrayによるタプルの例を示します。
['abc', 2, 5] [:matrix, 1,6, 3.14] ['family', 'is-sister', 'Carolyn', 'Elinor']
write(Lindaでのout操作)では上記のようなタプルをタプルスペースに 書き込みます。
take(Lindaでのin操作)やread(Linadでのrd操作)では上記のような 値のタプルの他に、ワイルドカードを用いたパターンを指定することが できます。C-Lindaではワイルドカードは*でしたが、 Rindaではnilで表現します。 nilの要素は全てのオブジェクトとマッチします。
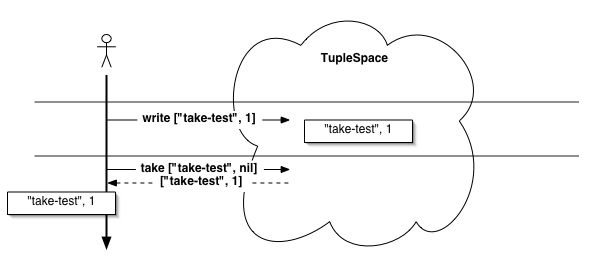
図8.2 writeとtake操作の実験。タプルがタプルスペースに置かれ、取り出される。
irbを用いてRinda::TupleSpaceのwriteとtakeを試してみましょう。 まず、さきほどのts01.rbを使って 'druby://localhost:12345'というURIでタプルスペースのサービスを起動します。
[ターミナル1]
% ruby ts01.rb
[ターミナル2]
% irb -r drb --simple-prompt
>> DRb.start_service
>> $ts = DRbObject.new_with_uri('druby://localhost:12345')
>> $ts.write(["take-test", 1])
>> $ts.take(["take-test", nil])
=> ["take-test", 1]
はじめに["take-test", 1]というタプルを$tsに置き、 次に["take-test", nil]というパターンで$tsから一つタプルを取り出しました。
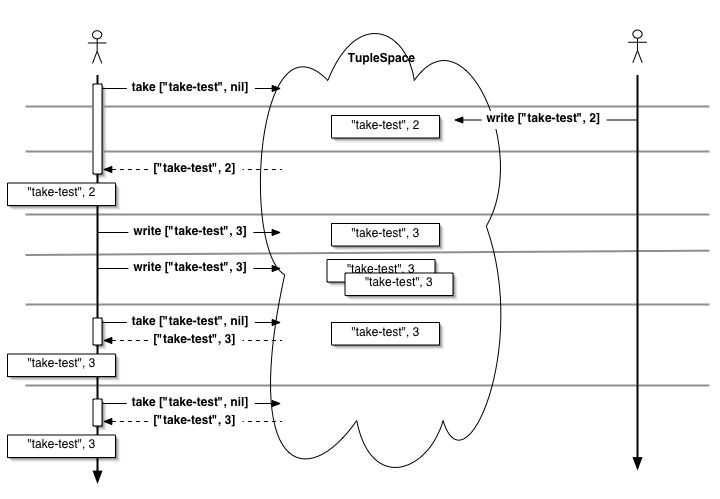
図8.3 takeするタプルがないとき、takeはブロックする。
すでに$tsにはタプルがなにもないはずですから、 次のtakeはブロックするはずです。
>> $ts.take(["take-test", nil])
もう一つターミナルを開いて、$tsにタプルを置いてみましょう。
[ターミナル3]
% irb -r drb --simple-prompt
>> DRb.start_service
>> $ts = DRbObject.new_with_uri('druby://localhost:12345')
>> $ts.write(["take-test", 2])
ターミナル2でtakeしているパターンにマッチしたタプルを置きました。 ターミナル2のブロックは解除され、プロンプトが出ているはずです。
[ターミナル2] >> $ts.take(["take-test", nil]) => ["take-test", 2] >>
タプルスペースに、同じ内容のタプルをいくつでもwriteすることができます。 タプルスペースにはwriteした数だけのタプルが置かれます。 ["take-test", 3]というタプルを二つwriteして、二つtakeしてみましょう。
[ターミナル2] >> $ts.write(["take-test", 3]) >> $ts.write(["take-test", 3]) >> $ts.take(["take-test", nil]) => ["take-test", 3] >> $ts.take(["take-test", nil]) => ["take-test", 3]
うまくいきましたね。
次に簡単な応用例を示します。 階乗をするサービスと、クライアントをRindaを使って書いてみましょう。 今回は階乗の要求は['fact', 数値1, 数値2]というタプルで表現し、 階乗の結果は['fact-answer', 数値1, 数値2, 結果]で表現します。 ['fact', m, n]という要求ではmからnまで順にかけ算をせよという要求で、 その結果が['fact-answer', m, n, ans]です。 ターミナル2をサーバーに、ターミナル3をクライアントに見立てて実験します。
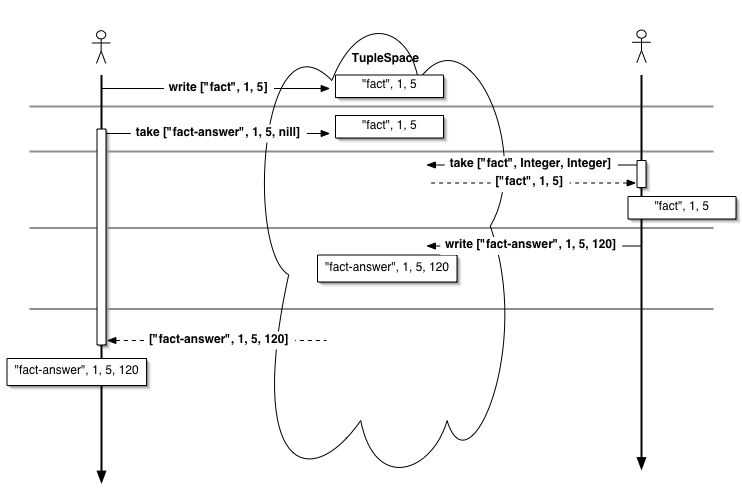
図8.4 階乗サービスの実験。階乗要求タプルと結果タプルによって表現する。
[ターミナル2] >> $ts.write(['fact', 1, 5]) >> res = $ts.take(['fact-answer', 1, 5, nil])
5の階乗を要求するタプルをwriteし、結果をtakeします。 階乗サービスが完了するまでtakeで待ち合わせます。
[ターミナル3]
>> tmp, m, n = $ts.take(['fact', Integer, Integer])
>> value = (m..n).inject(1) { |a, b| a * b }
>> $ts.write(['fact-answer', m, n, value])
サーバは['fact', Integer, Integer]をtakeし、 その数値を階乗して結果となるタプルを作成してwriteします。 このタプルがターミナル2のブロックを解除させるトリガーとなるはずです。
[ターミナル2] >> res = $ts.take(['fact-answer', 1, 5, nil]) ["fact-answer", 1, 5, 120] >> puts res[3] 120
このサービスをRubyスクリプトで書くと次のようになります。
List 8.2 ts01s.rb
# ts01s.rb
require 'drb/drb'
class FactServer
def initialize(ts)
@ts = ts
end
def main_loop
loop do
tuple = @ts.take(['fact', Integer, Integer])
m = tuple[1]
n = tuple[2]
value = (m..n).inject(1) { |a, b| a * b }
@ts.write(['fact-answer', m, n, value])
end
end
end
ts_uri = ARGV.shift || 'druby://localhost:12345'
DRb.start_service
$ts = DRbObject.new_with_uri(ts_uri)
FactServer.new($ts).main_loop
List 8.3 ts01c.rb
# ts01c.rb require 'drb/drb' def fact_client(ts, a, b) ts.write(['fact', a, b]) tuple = ts.take(['fact-answer', a, b, nil]) return tuple[3] end ts_uri = ARGV.shift || 'druby://localhost:12345' DRb.start_service $ts = DRbObject.new_with_uri(ts_uri) p fact_client($ts, 1, 5)
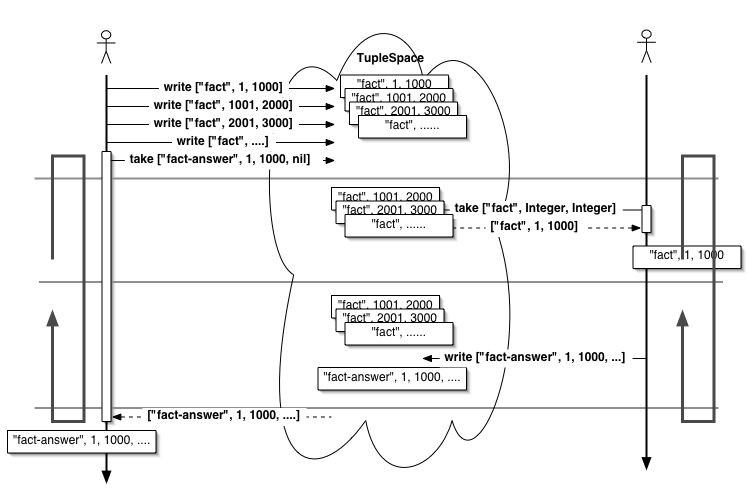
図8.5 階乗サービスの実験。階乗要求は分割して複数の要求として置かれる。
実行してみましょう。まずは、TupleSpaceの起動です。先ほどのターミナル1の スクリプトが動作していればそのままでもかまいません。
[ターミナル1] % ruby ts01.rb
次に階乗クライアントを起動します。 サーバでなくクライアントを先に起動するのは不思議な感じがしますか? *2 クライアントはサーバの起動を待って一時的に停止することでしょう。
[ターミナル2] % ruby ts01c.rb
最後に階乗サーバです。
[ターミナル3] % ruby ts01s.rb
階乗サーバが起動されたことで[ターミナル2]のクライアントは動きだします。
[ターミナル2] 120
もう一度クライアントを起動します。今度はすぐに答えが返ってきます。
[ターミナル2] % ruby ts01c.rb 120
階乗サーバーと階乗クライアントはお互いに直接通信するのではなく、 タプルスペースを経由して通信しています。 クライアントは階乗要求タプルを置いて、階乗結果タプルを待ちます。 サーバーは階乗要求タプルを取り出し、結果タプルを置きます。 タプルスペースを中心としたタプルの交換で複数のプロセスが協調するのです。 タプルスペースという「場」のおかげで、時間を気にせず待ち合わせが容易になります。
ここでクライアントを少し変更して、大きな階乗を求める場合に いくつかの範囲に分割して要求を出すように変更してみましょう。
List 8.4 ts01c2.rb
# ts01c2.rb
require 'drb/drb'
def fact_client(ts, a, b, n=1000)
req = []
a.step(b, n) { |head|
tail = [b, head + n - 1].min
req.push([head, tail])
ts.write(['fact', head, tail])
}
req.inject(1) { |value, range|
tuple = ts.take(['fact-answer', range[0], range[1], nil])
value * tuple[3]
}
end
ts_uri = ARGV.shift || 'druby://localhost:12345'
DRb.start_service
$ts = DRbObject.new_with_uri(ts_uri)
# p fact_client($ts, 1, 20000)
fact_client($ts, 1, 20000) # (注)
20000の階乗を1000ずつの範囲に分割して求めるクライアントです。 はじめに分割した階乗要求タプル(['fact', head, tail])を全てwriteし、 それから全ての結果を取り出してかけ算します。
階乗要求タプルのwriteと結果のtakeは次のようになります。
$ts.write(['fact', 1, 1000]) $ts.write(['fact', 1001, 2000]) $ts.write(['fact', 2001, 3000]) .... $ts.take(['fact-answer', 1, 1000, nil]) $ts.take(['fact-answer', 1001, 2000, nil]) $ts.take(['fact-answer', 2001, 3000, nil]) ...
階乗サーバが一つのプロセスの状態では速度はかわらず、むしろ通信の オーバーヘッドの分より時間がかかってしまうでしょう。 では階乗サーバをもっと用意したらどうでしょう。 別ホスト上で階乗サーバを起動し、 もしマルチプロセッサのホストであれば同じマシンで複数の階乗サーバを起動して 階乗の計算処理を分散させたら処理時間を短縮を期待できます。
例えば、別ホストで階乗サーバを起動するには次のようにしてからクライアントを 起動します。
[ターミナル4/別ホスト] % ruby ts01s.rb druby://yourhost:12345 [ターミナル2] % ruby ts01c2.rb
ところで、ts01c2.rbの最後の行は階乗だけを求めて印字していません。 実はサーバの構成を変えながら速度を測っていて気づいたのですが、 演算処理よりよりも巨大なBignumを文字列に変換する方がずっと時間がかかる ことがわかりました。 演算の速度に興味がある場合には印字処理の時間が邪魔をしないように印字を しないと良いでしょう。 結果に興味がある場合にはpなどで印字するように変更してください。
クライアントはタプルスペースという「場」のおかげで、 サーバの増減について何も知っている必要がありません。 実際に処理するサーバがいくつになってもクライアントは何ら変更する必要が ないところに注目してください。Lindaのモデルのおもしろさの一つですね。
Rindaの(そしてLindaの)基本となるwrite/takeの振る舞いを説明しました。
- データをタプルで表現する
- タプルをタプルスペースに置く
- タプルスペースからタプルを取り出す
というモデルであることが実感できたでしょうか?
8.2.3 readとread_all
takeとよく似た操作にreadがあります。 readはLindaのrd操作に相当するもので、パターンにマッチするタプルを見つけて そのコピーを返します。 もう一度ts01s.rbを使用して動作を確かめましょう。
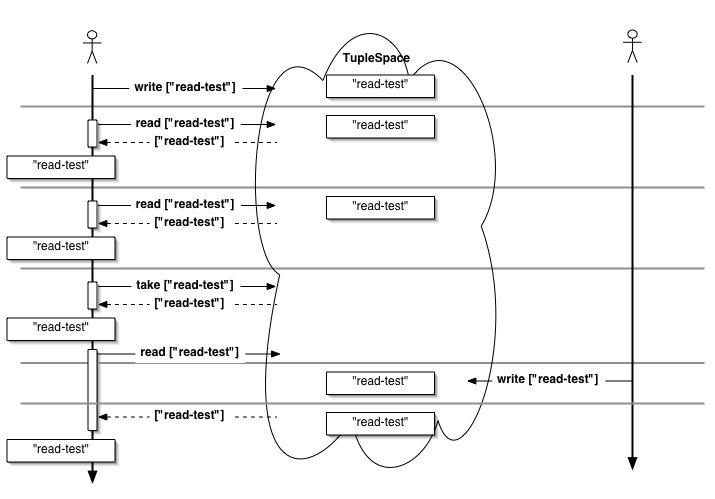
図8.6 read操作の実験。takeと同様にreadするタプルがないとき、readはブロックする。
[ターミナル1]
% ruby ts01.rb
[ターミナル2]
% irb -r drb --simple-prompt
>> DRb.start_service
>> $ts = DRbObject.new_with_uri('druby://localhost:12345')
>> $ts.write(["read-test"])
>> $ts.read(["read-test"])
=> ["read-test"]
readタプルを読み出すだけで、タプルスペースから削除することはありません。 もう一度やってみましょう。
>> $ts.read(["read-test"]) => ["read-test"]
二度目も成功しますね。これはreadではタプルが取り出されることがないためです。 タプルをtakeしてからreadするとブロックするはずです。
>> $ts.take(["read-test"]) => ["read-test"] >> $ts.read(["read-test"])
先ほどの実験のときと同じようにターミナル3でタプルをwriteして、 ブロックが解除されるか試してみます。
[ターミナル3]
% irb -r drb --simple-prompt
>> DRb.start_service
>> $ts = DRbObject.new_with_uri('druby://localhost:12345')
>> $ts.write(["read-test"])
[ターミナル2]
>> $ts.read(["read-test"])
=> ["read-test"]
>>
ブロックが解除され、プロンプトが表示されました。
Lindaにはありませんが、Rindaにはread_allというメソッドが用意されています。 read_allはパターンにマッチする全てのタプルのコピーを配列で返します。 マッチするタプルが一つもない場合には、空の配列([])を返します。 read_allは主にデバッグなどで重宝するのではないかと考えています。
[ターミナル2] >> $ts.read_all(["read-test"]) => [["read-test"]] >> $ts.take(["read-test"]) => ["read-test"] >> $ts.read_all(["read-test"]) => [] >> $ts.write(["read-test", 1]) >> $ts.write(["read-test", 2]) >> $ts.read_all(["read-test"、nil]) => [["read-test", 1], ["read-test", 2]]
8.2.4 タイムアウトとinp、rdp
Lindaのinpとrdpはそれぞれ、inとrd操作の即時復帰版です。 inがマッチするタプルがタプルスペースに置かれるまでブロックする 完了復帰であるのに対して、inpはタプルがなければ即時にエラーと なります。
Rindaにはinpとrdpがありませんが、タイムアウトを使って同様な 効果を得ることができます。
takeメソッドとreadメソッドには第二引数にタイムアウトを指定することができます。
take(pattern, sec=nil)-
patternにマッチするタプルを取り出して返す。 secは処理をあきらめる時間を秒で指定する。 nilを与えるとタイムアウトせず完了復帰となる。デフォルトはnilである。
read(pattern, sec=nil)-
patternにマッチするタプルのコピーを一つ返す。 secは処理をあきらめる時間を秒で指定する。 nilを与えるとタイムアウトせず完了復帰となる。デフォルトはnilである。
タイムアウトに0を指定すると、 Lindaのinp操作と同様に即時復帰のtakeという意味になります。 takeがタイムアウトすると、Rinda::RequestExpiredErrorという例外が発生します。
いま$tsにタプルはありませんから、やはりtakeはブロックしてしまいます。 タイムアウトに0を指定して、実験してみましょう。
[ターミナル2]
>> $ts.take(["timeout-test"], 0)
Rinda::RequestExpiredError: Rinda::RequestExpiredError
........
>> $ts.write(["timeout-test"])
>> $ts.take(["timeout-test"], 0)
=> ["timeout-test"]
readもwriteと同じようにタイムアウトを秒で指定することができます。 0を指定すると、Lindaのrdp操作と同じ機能になります。
[ターミナル2]
>> $ts.read(["timeout-test"], 0)
Rinda::RequestExpiredError: Rinda::RequestExpiredError
........
タイムアウトの時間はちょっと注意が必要です。 タイムアウトしている操作を検査するのはkeeperスレッドで、 その検査のタイミングはデフォルトで60秒となっています。 0の場合にはタイムアウトかどうか直ちに検査されますが、 0より大きい場合、タイムアウトの例外が発生するのは、 次回のkeeperスレッドの起動のあとまで遅れる点に注意が必要です。
[ターミナル2] >> $ts.take(["timeout-test"], 5)
しばらくブロックしたのち、60秒以内に例外が発生すことでしょう。 これはkeeperスレッドの活性化の間隔を調整することで改善できます。 その間隔はTupleSpaceの生成のパラメータで指定します。 keeperスレッドがあまり頻繁に動作するとパフォーマンスに問題が出る 可能性があります。ほどほどに調整してみてください。
[ターミナル2] >> $ts2 = Rinda::TupleSpace.new(5) >> $ts2.take(["timeout-test"], 5)
8.2.5 タプルとパターンマッチング
Rindaではタプルとtakeのパターンの比較はArrayの各要素を「===」で比較します。 タプルとパターンの要素数が一致し、 各要素が「===」で真になる場合にマッチしたことになります。
これによって、nilによるワイルドカードだけでなく より複雑なパターンマッチングを行えます。 例えばRegexpによる文字列の比較や、クラスとインスタスによる比較が可能です。
先頭の要素が'add'または'sub'が含まれ(正規表現/add|sub/)、 第二、第三要素が整数(Integer)のタプルをtakeしてみましょう。
[ターミナル2] >> $ts.take([/add|sub/, Integer, Integer])
はじめに第二要素がFloatのタプル(['add', 2.5, 5])をwriteしてみます。 クラスが異なるので===がtrueとならず、マッチしないはずです。
[ターミナル1] >> $ts.write(['add', 2.5, 5])
まだ[ターミナル2]のtakeはブロックしたままですね?
続いて['add', 2, 5]をwriteします。[ターミナル2]が要求するタプルと マッチしていますから、takeが完了するはずです。
[ターミナル1] >> $ts.write(['add', 2, 5]) [ターミナル2] >> $ts.take([/add|sub/, Integer, Integer]) => ["add", 2, 5]
正規表現やRange、クラスをうまく用いると、 複雑なパターンを記述できます。 性能をあまり重視しないのであれば、データベースの様にも使用できます *3。
8.3 基本分散データ構造体
Lindaはタプルという要素をタプルスペースで出し入れするモデルで、 同じ要素を複数持つことができる集合データ構造ーBagであると言えます。 しかし、タプルの表現やタプル操作を工夫することによって Bag以外にもさまざまデータ構造として応用することができます。
「並列プログラムの作り方」(N.Carriero/D.Gelernter)では、 タプルスペースを使った基本分散データ構造体について述べています。 主に以下の三つに分類しています。
- Bag - 要素がすべて同じ、または区別できないような構造体
- Struct, Hash - 要素が名前で区別されるような構造体
- Array, Stream - 要素が位置で区別されるような構造体
この節ではこれら基本分散データ構造体について説明します。 基本分散データ構造体には、TupleSpaceを利用する際のヒントがたくさん 含まれています。
8.3.1 Bag
Bagは同じ要素を複数持つことができる、集合構造の一種です。 また要素に順序がないことも特徴です。 TupleSpaceへのもっとも自然なデータ構造と言えます。 Bagには要素の追加/要素の削除の二つの操作があります。 TupleSpaceではwriteとtakeが追加と削除にあたります。
$ts.write(['fact', 1, 5])
は要素の追加、
$ts.take(['fact', Integer, Integer])
は要素の削除です。 よくある使い方として先の階乗のような複数サーバ型の処理における タスクのバッグがあげられます。
$ts.write(['fact', 1, 1000]) $ts.write(['fact', 1001, 2000]) $ts.write(['fact', 2001, 3000]) .... $ts.take(['fact-answer', 1, 1000, nil]) $ts.take(['fact-answer', 1001, 2000, nil]) $ts.take(['fact-answer', 2001, 3000, nil]) ...
Bagの使用例として、TupleSpaceによるセマフォを示します。 セマフォにはdownとupの二つの操作があります。 downは資源を獲得する操作、upは資源を解放する操作です。 TupleSpaceにあるタプルを資源と考えると、 セマフォは単にタプルをwrite/takeすることで、 つまりBagへの要素の追加/削除をすることで実現できます。 セマフォの資源数がnであるカウンティングセマフォも、 n個のタプルを使って表現することができます。
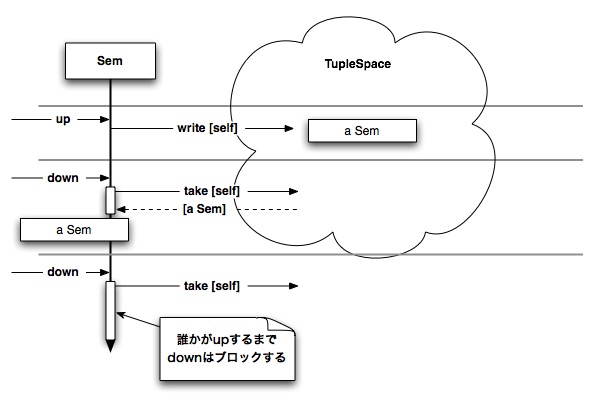
図8.7 TupleSpaceを用いたセマフォの実装。downはwriteで、upはtakeで実装される。
class Sem
include DRbUndumped
def initialize(ts, n, name=nil)
@ts = ts
@name = name || self
n.times { up }
end
attr_reader :name
def synchronize
succ = down
yield
ensure
up if succ
end
private
def up
@ts.write(key)
end
def down
@ts.take(key)
return true
end
def key
[@name]
end
end
Semのごく簡単な使用例を示します。
require 'rinda/tuplespace' sem = Sem.new(Rinda::TupleSpace.new, 1) sem.synchronize do .... end
keyメソッドはSemのインスタンスごとに一意なタプルを生成するメソッドです。 返すのは@nameだけを要素にとるこのようなタプル
[@name]
です。@nameはアプリケーションが指定できますが、 その値はシステムで一意となる必要があります。 @nameのデフォルト値はシステムで一意であることを保証するために、 Sem自身としました。 @tsのタプルスペースがSemと同じプロセスであれば、Semのインスタンス自体が タプルに含まれことになります。 @tsのタプルスペースがリモートのオブジェクトであれば、 Semのインスタンスを参照するDRbObjectが要素となります。 一意な名前についてはまたあとで議論したいと思います。
セマフォをRinda::TupleSpaceで実装できるということを示しましたが、 実はセマフォはQueueで簡単に実装することが可能です。
require 'thread'
class SemQ
def initialize(n)
@queue = Queue.new
n.times { up }
end
def synchronize
succ = down
yield
ensure
up if succ
end
private
def up
@queue.push(true)
end
def down
@queue.pop
end
end
TupleSpaceを利用するSemの方がTupleSpaceを準備する必要がある分、 少し面倒くさいように思います。 セマフォの利用自体が目的の場合はQueueを上手に使う方が良いでしょう。
8.3.2 Struct, Hash
次に名前と値を関連付けて扱うデータ構造について説明します。 これはRubyではStructやHashに近いデータ構造です。
名前と値を組にしたタプルを使ってデータを表現するのが基本です。
[key, value]
例えば'guid'というフィールドを0で初期化するには次のようにします。
ts.write(['guid', 0])
更新はtakeとwriteを組み合わせます。
key, value = ts.take(['guid', nil]) ts.write(['guid', name + 1])
名前に相当する部分はタプルのただ一つの要素である必要はありません。 複数の要素を名前と考えることも可能です。 例えば、オブジェクトの一つの属性を表すのに、
[object, attr_name, value]
というように、オブジェクトと属性名の二つの要素を名前とみなすことができます。
RubyではStruct.new次のように構造体を定義します。
>> S = Struct.new(:foo, :bar) >> s = S.new(1, 'bar') => #<struct S foo=1, bar="bar"> >> s.foo = s.foo + 1 >> s.foo => 2
これをTupleSpaceで書くと次のようになります。
>> s = Object.new >> ts = Rinda::TupleSpace.new >> ts.write([s, 'foo', 1]) >> ts.write([s, 'bar', 'bar']) >> tuple = ts.take([s, 'foo', nil]) >> ts.write([s, 'foo', tuple[1] + 1])
データの更新のために、一度takeしてからwriteするのがミソです。 take中は別のプロセスがこのフィールドをtakeできないので、 writeで書き戻すまでは排他制御されることになります。
この分散データ構造体を用いて、バリア同期を実装してみましょう。
まずバリア同期について簡単に説明します。 複数の並行して動作するプロセス/スレッドがあるとします。 全てのプロセスがプログラムのフェーズnを完了するまで、 フェーズn+1の処理を開始することを防止する同期メカニズムを バリア、あるいはバリア同期といいます。 それぞれのプロセスがバリアに到達すると、すべてのプロセスが バリアに到達するまで停止します。 最後のプロセスがバリアに到達するとバリアで停止していた プロセスは再開されます。
バリア同期は、バリア同期の名前(key)と待ちプロセス数(n)を組にした [key, n]というタプルで実装できます。 n個のプロセスが待ち合わせをするバリアの初期化はタプル[key, n]を writeすることになります。
class Barrier
def initialize(ts、n, name=nil)
@ts = ts
@name = name || self
@ts.write([key, n])
end
def key
@name
end
end
バリアに到達したときには次のようにタプルを操作して待ち合わせします。 [key, nil]をtakeして、数値を一つ減じて再びwriteします。 そして最後に[key, 0]をreadして待ちプロセス数が0になるまでブロックします。 n個のプロセスがバリアに到達すると[key, 0]がwriteされますから、 readのブロックが解除され処理が再開されるのです。 [key, 0]で待てるところがTupleSpaceのかっこいいところですね。
class Barrier
def sync
tmp, val = @ts.take([key, nil])
@ts.write([key, val - 1])
@ts.read([key, 0])
end
end
takeしてからwriteするまでの期間、Mutexのsynchronizeなどの排他制御を 行っていないために競合状態になりそうに見えますが実際にはそうなりません。 take([key, nil])によって、タプルは一時タプルスペースから 取り除かれているため、write([key, val-1])するまで 他のプロセスは待ちプロセス数のタプルをtakeできないのです。 takeからwriteまでの期間は、他のプロセスのtake([key, nil])はブロック されるので安心して値を操作できるのです。 このテクニックはなかなか便利に使えそうです。
最後に実用的な視点はちょっと忘れ、パズルを解く気分で この操作を一般化してメソッドにしてみましょう。
タプルスペース、初期値となるStructやHashのインスタンス、 オブジェクトの識別子を与えて、タプルスペースにStructのような データ構造を生成します。
注目してほしいのはこのTSStructでは既存の要素の置き換えはできても 新しい要素の追加はできないという点です。
class TSStruct
def initialize(ts, name, struct=nil)
@ts = ts
@name = name || self
return unless struct
struct.each_pair do |key, value|
@ts.write([@name, key, value])
end
end
attr_reader :name
def [](key)
tuple = @ts.read([name, key, nil])
tuple[2]
end
def []=(key, value)
replace(key) { |old_value| value }
end
def replace(key)
tuple = @ts.take([name, key, nil])
tuple[2] = yield(tuple[2])
ensure
@ts.write(tuple) if tuple
end
end
8.3.3 Array, Stream
最後のデータ構造は、要素に順序や位置が存在するデータ構造です。 位置と値を組にしたタプルを使って表現されます。 行列や配列、ストリームといった集合構造がこれに含まれます。
各要素は位置と値からなる次のようなタプル
[index, value]
あるいはオブジェクト、位置と値で構成されるタプルを用いて表現します。
[object, index, value]
たとえば、'a'という2x2の行列を次のように表現できます。
['a', 0, 0, 1.0] ['a', 1, 0, 0.0] ['a', 0, 1, 0.0] ['a', 1, 1, 1.0]
表現できるとはいうものの、行列のすべての要素をタプルにするのは やりすぎかもしれません。 あらゆる要素の操作ごとに、いつもスレッドの同期の処理や TupleSpaceをリモートに置く場合にはさらにプロセス間通信のオーバヘッドが 発生してしまいます。
一つのプロセスだけが追記し、一つのプロセスだけが読み出すQueueは 位置と値で表現した配列によって表現できます。
ストリームの名前を'stream'とします。ストリームの要素は次のような 位置のついたタプルとなります。
['stream', 1, value1] ['stream', 2, value2] ['stream', 3, value3] ....
下のように配列の末尾は書き手のオブジェクトが管理した場合、 複数の書き手が一つのストリームに追記することができません。
class Stream
def initialize(ts, name)
@ts = ts
@name = name
@tail = 0
end
attr_reader :name
def push(value)
@ts.write([name, @tail, value])
@tail += 1
end
end
複数のプロセスが追記可能にするために、 末尾のインデックスもタプルスペースに管理させてしまうと良いでしょう。 先に説明したStructやHashのようなデータ構造を思い出してください。 名前と値を組にしたタプルを使って次のように表現します。
['stream', 'tail', 末尾]
複数のプロセスが追記できるストリームは次のような定義になります。 なお実用的なストリームにするにはもう少し工夫が必要です。 ここではアルゴリズムを感じてください。
class Stream
def initialize(ts, name)
@ts = ts
@name = name
@ts.write([name, 'tail', 0])
end
attr_reader :name
def write(value)
tuple = @ts.take([name, 'tail', nil])
tail = tuple[2] + 1
@ts.write([name, tail, value])
@ts.write([name, 'tail', tail])
end
end
ストリームからの要素の取り出しには二種類あります。 一つは読み出すたびに要素が消費されるinストリーム、 もう一つは読み出しても要素が消費されないrdストリームです。
はじめに読み出しても要素が消費されないrdストリームを説明します。 rdストリームは、読み出してもストリーム自体になんら変化を与えません。 要素の読み出しにはreadを使い、読み出す先頭のインデックスは読み手だけが 管理します。
class RDStream
def initialize(ts, name)
@ts = ts
@name = name
@head = 0
end
def read
tuple = @ts.read([@name, @head, nil])
@head += 1
return tuple[2]
end
end
インスタンス変数@headはこの読み手にとってのストリームの先頭を表します。 @headを一つずつ大きくしながらストリームの要素を@ts.readして返します。 @headがストリームの要素のインデックスを超えたとき、 read操作はブロックします。これによってRDStreamのreadも ストリームに新しい要素がwriteされるまでブロックすることになります。
次にinストリームについて考えます。 inストリームは読み出した要素をストリームから削除します。 ただ一つのプロセスが読み出す場合にはrdストリームの@ts.readを@ts.takeに 変更するだけで良さそうです。
class INStream
def initialize(ts, name)
@ts = ts
@name = name
@head = 0
end
def take
tuple = @ts.take([@name, @head, nil])
@head += 1
return tuple[2]
end
end
しかし、複数のプロセスが読み出す場合を考えてみましょう。 @headはそれぞれのプロセスのオブジェクトで管理されていますので、 一度いずれかのプロセスがストリームから要素を取り除いてしまうと、 別のプロセスは読み出すことができなくなります。 つまり、ただ一つのプロセスの読み出ししか成功しないということです。
複数のプロセスが追記するストリームを思い出してください。 末尾の管理と同様に先頭のインデックスもタプルスペースで管理すれば、 @headのインデックスを複数のプロセスで共有できます。 次のようなタプルを使って@headも管理させましょう。
['stream', 'head', 先頭]
classとして定義すると次のようになります。
class INStream
def initialize(ts, name)
@ts = ts
@name = name
@ts.write([@name, 'tail', 0])
@ts.write([@name, 'head', 0])
end
def write(value)
tuple = @ts.take([@name, 'tail', nil])
tail = tuple[2] + 1
@ts.write([@name, tail, value])
@ts.write([@name, 'tail', tail])
end
def take
tuple = @ts.take([@name, 'head', nil])
head = tuple[2]
tuple = @ts.take([@name, head, nil])
@ts.write([@name, 'head', head + 1])
end
end
さて、みなさんはそろそろ気づいているかもしれません。 INStreamの機能はRubyに用意されているQueueと同じですね。
8.4 アプリケーションに向けて
タプルスペースを利用した基本分散データ構造体について見てきました。 ちょっとしたアプリケーションに必要となる基本的なアルゴリズムを 感じることができたと思います。
これらのデータ構造をアプリケーションから簡単に利用できるような クラスにするにはどうしたら良いでしょうか。 Structのような操作を一般化したTSStructを改造しながら考えていきましょう。
TSStructはStructのようにフィールド名をSymbolで指定して 値を取り出したり、設定したりできるデータ構造です。 タプルスペースと初期値となるStructやHashのインスタンス、 オブジェクトの識別子を与えて生成します。
TSStructはフィールドの内容を置き換えることができますが、 新たなフィールドを追加したり、フィールドそのものを 削除することはできません。
class TSStruct
def initialize(ts, name, struct)
@ts = ts
@name = name
struct.each_pair do |key, value|
@ts.write([@name, key, value])
end
end
attr_reader :name
def [](key)
tuple = @ts.read([name, key, nil])
tuple[2]
end
def []=(key, value)
replace(key) { |old_value| value }
end
def replace(key)
tuple = @ts.take([name, key, nil])
tuple[2] = yield(tuple[2])
ensure
@ts.write(tuple) if tuple
end
end
どのデータ構造でも一意な識別子となるnameを指定するようになっていたのを 覚えていますか? SemやBarrierやRDStreamなどのオブジェクトを指し示すには 何らかの名前が必要になります。 名前はどのように生成すればいでしょうか。 タプルスペースは本来、Bagであることを説明しました。 タプルスペースには要素の重複を検査する機構はないのです。 この点に注意して名前の生成について考えてみましょう。
はじめに、タプルスペースが一つのプロセスの中だけで利用される場合についてです。 プロセスの中で一意な値を簡単に取得する方法の一つに、Objectそのものを 値とする、という方法があります。 次のようにObjectをnewするだけで、一意な値が手に入ります。
key = Object.new key2 = Object.new p (key == key2) # → false
単一のプロセスであればObjectそのものは一意な値として利用しやすいものです。 Objectが存在する間、GCされるまで、同じidのObjectが生成されることはありません。 Object.newの代わりに、データ構造を管理するオブジェクト自身を 一意な値とすることもできます。 次のように @name = name || selfとしてデフォルト値をselfにすればよいでしょう。
class TSStruct
def initialize(ts, name, struct)
@ts = ts
@name = name || self
struct.each_pair do |key, value|
@ts.write([@name, key, value])
end
end
...
end
TSStructそのものもタプルの要素としてTupleSpaceにwriteされることになります。
dRubyを介して複数のプロセスから利用されるとしたらどうでしょう。 一つはDRbUndumpedをincludeしてnameがリモートに転送される際に DRbObjectに変換してしまう、という作戦があげられます。
class TSStruct include DRbUndumped ... end
DRbObjectはオブジェクトの存在するプロセス(実際にはそのプロセスで起動された DRbServer)を決定するURIと、そのプロセスの中でオブジェクトを一意に決定する 識別子でできています。 ですからDRbObjectもTSStructのデータを保持しているTupleSpaceの中でも一意であると 考えることができます。
TSStructを生成するプロセスと、その内容を保持するTupleSpaceのプロセスを 分ける場合、ちょっとした問題があります。 一つはパフォーマンスの問題、もう一つは寿命の問題です。
TSStructの要素へのアクセスは、いつも生成したプロセスとTupleSpaceのプロセスの 両方のメソッドが起動されてしまいます。
[利用者] → [生成担当] → [TupleSpace]
TSStructのメソッドを利用者のプロセスも持ちTupleSpaceの内容を更新する、 あるいはTupleSpaceのTSStructのメソッドを利用する方がRMIが少なくて済みます。 利用者がTSStructのメソッドを持つ方がかっこいい*4ですが、 TupleSpaceがTSStructのメソッドを持つ方が効率が良いでしょう。
後者はやっかいです。もし生成担当のプロセスが終了してしまうと、 そのTSStructは利用不能になり、TupleSpaceにも無駄なタプルが残ってしまいます。 また名前の一意性も問題があります。 dRubyのURIはそのプロセスが起動している間に限ってユニークなものです。 生成担当プロセスが終了後に新たなdRubyのサービスが起動したときに、 再び同じポートが割り当てられてしまう可能性も少ないながらもあるわけです。
問題が少なくGCの問題も心配しなくてよいのは、TupleSpaceを持つプロセスが TSStructの生成も担当するようにすることです。 バックエンドにTupleSpaceが動いていることが陽に見えなくなるのは寂しいですが、 実用的なアプリケーションでは素朴に書くことも重要となるでしょう。
8.5 Rindaの拡張 - タプルの有効期限
私たちはしばしば間違いを犯します。 スクリプトは簡単にバグを含んでしまうものです。 スクリプトの開発中では、修正しながらプロセスをなんども起動するのはよくある ことです。 こんなとき、複数存在してはいけないタプルを置き忘れてしまったらどうなるでしょう。 タプルスペースとアプリケーションが一つのプロセスにあるときは、 タプルスペースも再起動されるためにタプルを置き忘れてしまうことはありません。 しかし、タプルスペースを提供するプロセスと、それを利用するアプリケーションの プロセスが異なる場合にはよく発生する状況です。 アプリケーションが正常に終了する/終了できる状況では、 アプリケーションが責任を持って後始末してから終了すればよいのですが、 いつも後始末ができるとも限りません。
Rindaには主に不慮の事態を念頭にタプルを自動的に削除するしかけを 用意しています。
8.5.1 有効期限とRenewer
Rindaのタプルには有効期限を設定することができます。 有効期限が過ぎたタプルは、タプルスペースから自動的に削除されます。 これにより、アプリケーションが不測の事態(バグなど)でタプルをおいたまま 終了してしまっても、なんとか切り抜けることができるかもしれません。
有効期限は次のようにwriteの第二引数で指定します。
@ts.write(tuple, sec)
有効期限は「あとsec秒」と設定されます。 sec秒経つと、tupleはタプルスペースから自動的に削除されます。 nilを与えると有効期限は無限となり、自動的な削除は行われません。 secを指定しない場合、secはnilで有効期限は設定されないことになります。
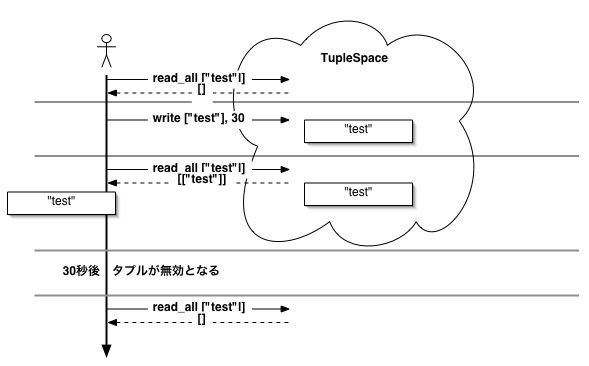
図8.8 30秒後にタプルの有効期限が切れ、自動的に削除される。
% irb -r rinda/tuplespace --simple-prompt >> ts.read_all(['test']) => [] >> ts.write(['test'], 30) >> ts.read_all(['test']) => [["test"]] >> sleep(30) >> ts.read_all(['test']) => []
secには数値とnilだけでなく、Renewerというオブジェクトを与えることが できます。Renewerはrenewというメソッドを持つオブジェクトです。 Renewerは、renewメソッドが呼ばれたら延長したい秒数を返さなくてはなりません。 renewメソッドがtrueを返すと、タプルの有効期限が過ぎたことを示し、 タプルはすぐに削除されます。 Renewerを使うと、延長する時間をアプリケーションの状態に応じて 変化させることができます。
RindaにはRinda::SimpleRenewerというクラスが用意されています。 SimpleRenewerの定義は次のような簡単なものです。
class SimpleRenewer
include DRbUndumped
def initialize(sec=180)
@sec = sec
end
def renew
@sec
end
end
renewメソッドは単に180を返すだけです。 ミソはSimpleRenewerはDRbUndumpedをincludeしており、参照渡しとなる点です。 SimpleRenewerをwriteの第二引数に時間の代わりに与えると、有効期限のたびに renewメソッドが呼び返されます。 もしアプリケーションがタプルを置き忘れたまま終了してしまった場合、 どうなるでしょう。 有効期限が切れそうになると、タプルスペースはSimpleRenewerのrenewを 呼び返します。しかし、このときはすでにSimpleRenewerの配置してあった アプリケーションは終了しているので、renewの呼び出しは失敗します。 タプルスペースはrenewの呼び出しが失敗したことを捉え、 タプルを削除します。 アプリケーションがタプルを置き忘れても、次回の有効期限の更新の際に タプルスペースがそれに気づき削除することができるわけです。
Renewerが有効期限の検査の間隔はrenewの返した秒数によって決まります。 逆に言うと、アプリケーションが停止した場合でも検査の間隔の間はタプルが 置き忘れたままになる可能性があるということです。 Renewerは更新手続きにdRubyのメソッド呼び出しが必要で オーバーヘッドが発生しますから、 極端に間隔を短くするとパフォーマンスに影響します。 困らない程度にほどほどの長さを指定するようにしましょう。
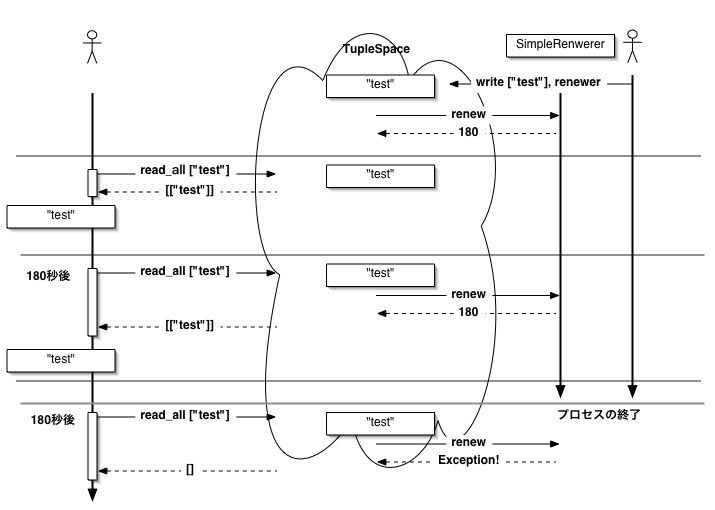
図8.9 SimpleRenewerを持つプロセスが終了すると、更新が失敗しタプルは削除される。
8.5.2 TupleEntryを用いた明示的なキャンセル
writeしたタプルを明示的にキャンセルする方法も提供されています。 ただし、TupleSpaceとアプリケーションのプロセスが異なる場合には ちょっと使いにくい部分があるため、Renewerを利用する方が安心です。
TupleSpaceのメソッドwriteは実は値を返します。 writeが返すのはTupleEntryで、TupleEntryを経由して タプルスペースに置いたタプルの操作を行うことができます。 TupleEntryの主なメソッドは次の通りです。
cancel-
タプルの有効期限を過去にして、無効なタプルとします。 タプルはタプルスペースから削除されます。
renew(sec_or_renewer)-
タプルの有効期限を更新します。更新する秒数か、Renewerオブジェクトを 与えることができます。 nilを与えると無限の有効期限を指定したことになります。
こんな風に使います。
@entry = @ts.write(['foo', 'bar']) ... @entry.cancel
writeしたタプルが誰かにtakeされていても、cancel操作は失敗しません。
TupleEntryはwrite操作の際にTupleSpaceの内部で自動的に作られるオブジェクトです。 対応するタプルがtakeされるとTupleEntryもTupleSpaceから忘れられます。 ここで注意が必要なのは、TupleEntryの寿命です。 TupleSpaceを配置したプロセスとタプルをwriteしたプロセスが同じプロセスであれば 問題ないのですが、異なるプロセスの場合にはGC問題が発生します。 別プロセスがwriteの戻り値を保持していても、それはTupleEntryを参照する DRbObjectを保持しているのであって、TupleEntryそのものを参照しているわけでは ありません。 takeされてしまうとTupleEntryを参照するオブジェクトがなくなり、 GCされてしまうのです。
これを回避するには二つ方法があります。
- TupleSpaceのサーバでTimerIdConv*5などの 仕掛けを用い、dRubyで参照させているオブジェクトのGCを抑制する。
- takeしない。またはtakeする予定のタプルにはTupleEntryによる 操作をあきらめる。
前者はTupleSpaceをサービスしているプロセスで、GCを抑制する仕掛けを 入れることでtakeされてもTupleEntryがGCされないようにするものです。
後者はアプリケーションを工夫して、takeする可能性のないタプルだけを TupleEntryで操作するように回避する方法です。 どちらも多少面倒ですね。
プロセスが分かれることが前提であれば、Renewerを用いた方が確実でしょう。
8.6 Rindaの拡張 - notify
RindaにはLindaを拡張した機能がいくつかあります。 notifyは興味のあるタプルの追加と削除をイベントとして通知する機能です。 takeやreadと同様なパターンマッチングでタプルを指定して、 マッチするタプルの追加や削除のイベントを受け取ることができます。 特定のタプルが削除されたことを捉えたり、簡単なデバッグなどに使用します。
通知されるイベントには "write"と"take"、"delete"の三種類のイベント種があります。
- "write"イベント --- writeによってタプルがタプルスペースに追加されたことを示します。
- "take"イベント --- takeによってタプルがタプルスペースから削除されたことを示します。
- "delete"イベント --- 有効期限切れや、cancelによってタプルがタプルスペースから削除されたことを 示します。
イベントははこれらのイベント種と原因となったタプルを組にした タプルにより表現されます。
たとえば、以下のようにタプルをwriteすると
ts.write(["Hello", "World"])
次のようなイベントが通知されます。
["write", ["Hello", "World"]]
takeも同様です。
ts.take(["Hello", nil])
では"take"が通知されます。
["take", ["Hello", "World"]]
実際に通知を受けるにはスクリプトをどう書けばよいか説明します。 通知はTupleSpaceのnotifyメソッドを使います。 notifyはイベント通知を懇請するメソッドで、興味のあるイベント種と タプルをパターンで指定します。
notify(event, pattern, sec=nil)-
タプル空間で発生するイベントの通知を懇請します。 patternにマッチするタプルに関するイベントを受けとることができます。 eventは興味のあるイベント種を指定します。タプルの要素のマッチング規則と 同様なので、nilを与えるとすべてのイベント種を通知します。 notifyはNotifyTemplateEntryというオブジェクトを返します。 secで指定した期間がすぎるとイベント通知は終了します。 イベント通知が終了すると、最後のイベントとして"close"イベントが 発生します。
notifyが返すNotifyTemplateEntryは、通知されたイベントを取り出す口となる オブジェクトです。
NotifyTemplateEntryの主なメソッドを示します。
each-
イベントが発生するたびにブロックを呼び出します。 ブロックにはイベント種と原因となったタプルが渡されます。 たとえば次のような値が渡されます。
["write", ["foo", "bar"]]
pop-
イベントを一つ取り出します。イベントが届いていない場合、 イベントが届くまでブロックします。
cancel-
イベント通知の懇請をキャンセルします。 これ以降、新しいイベントは届かなくなります。 cancel以前に到着したイベントはpopで取り出すことができます。 最後に発生したイベントの次に["close"]という疑似的なイベントが 届きます。
実際にイベントを取得する一連のコードを紹介します。
# イベント通知の懇請 notifier = ts.notify(nil, ['test', nil]) # イベントの取り出し notifier.each do |event, tuple| ... end
notifyで指定するパターンごとにNotifyTemplateEntryが生成されます。 このため、パターンごとに通知のキューが分かれることになりますから、 複数のパターンのイベントの順序を正確に知ることはできません。 たとえば、['test', nil]というパターンと['name', 'rwiki' nil]というパターンの 二つのパターンで指定するイベントは、それぞれことなるキューになります。 異なるパターンのイベントを同時に観察する仕掛けは用意されていません。 Queueを使って複数のキューをまとめ擬似的に一つに見せることは可能ですが、 イベントの順序を保証することはできません。 以下に二つのnotifyを一つにまとめるスクリプト片を載せます。
notify_test = ts.notify(nil, ['test', nil])
notify_name = ts.notify(nil, ['name', 'rwiki' nil])
queue = Queue.new
Thread.new do
notify_test.each do |event|
queue.push(event)
end
end
Thread.new do
notify_name.each do |event|
queue.push([event])
end
end
....
while true
p queue.pop
end
classで書き直してみましょう。 List 8.5 multiplenotify.rb
# multiplenotify.rb
require 'drb/drb'
require 'rinda/rinda'
require 'rinda/tuplespace'
class MultipleNotify
def initialize(ts, event, ary)
@queue = Queue.new
@entry = []
ary.each do |pattern|
make_listener(ts, event, pattern)
end
end
def pop
@queue.pop
end
def make_listener(ts, event, pattern)
entry = ts.notify(event, pattern)
@entry.push(entry)
Thread.new do
entry.each do |ev|
@queue.push(ev)
end
end
end
end
先ほどのスクリプトと同じように動作するスクリプトは次のようになります。
mn = MultipleNotify.new(ts, nil, [['test', nil], ['name', 'rwiki' nil]]) while true p mn.pop end
8.7 Hashタプル
これまで紹介してきたタプルはArrayを用いたLindaによく似たタプルでした。 Rindaでは実験的にHashを用いたタプルを追加しました。 Arrayタプルに対して、Hashタプルには タプルの意味を伝えやすい という メリットがあります。
Arrayタプルでは要素の順序で意味を表現しますが、Hashタプルではキーを 使用しますから意味が伝わりやすくなります。
write、read、noifyなどタプルを与えるメソッドではArrayによるタプルだけでなく、 Hashによるタプルを使うことができます。
パターンマッチングの規則もArrayタプルとほぼ同様です。 Hashタプルとパターンマッチングには以下の制限があります。
- HashタプルのキーはStringのみ
- パターンで値をnil(ワイルドカード)を与えた場合、 その要素のキーを持つタプルとマッチする。
Hashタプルの例を示します。
{"name" => "seki", "age" => 0x20}
{"kind" => "family", "name" => "Elinor", "sister" => "Carolyn"]
{"request" => "fact", "lower" => 1, "upper" => 10 }
{"answer" => "fact", "lower" => 1, "upper" => 10, "value" => 3628800 }
String以外のキーをもつHashを与えるとRinda::InvalidHashTupleKey例外が 発生します。
パターンマッチングの例を見てみましょう。
パターン: {"name" => nil, "age" => Integer}
このパターンは次の条件を満たすタプルと適合します。
- "name"というキーの要素を持っていること。
- "age"というキーの値がIntegerであること。
- 要素数が2であること。
このパターンといくつかのタプルをパターンマッチングさせることにしましょう。
- {"name" => "m_seki", "age" => 32.5} # ×
- {"name" => "seki", "age" => 0x20} # ○
- {"name" => "seki", "age" => 0x20, "url" => "http://www.druby.org"} # ×
- {"age" => 0x20 } # ×
タプル(1)には"name"、"age"の他に"url"という要素がありますが、 パターンで指定されている二つの要素はマッチしていますからパターンマッチングが 成功します。
タプル(3)は要素数が異なるので失敗します。
タプル(4)には"name"がありません。たとえパターンがワイルドカードで あっても"name"の要素を持っていなくてはパターンに適合しません。
先に作成した階乗を求めるサービスをHashタプルでもう一度書き直してみましょう。 要求タプルと結果タプルはそれぞれ次の形式とします。
{ "request" => "fact", "range" => Range }
{ "answer" => "fact", "range" => Range, "fact" => Integer }
もとのバージョンでは配列で表現していましたが、Hashタプル版では フィールドの意味が明解になっています。
List 8.6 ts01sh.rb
# ts01sh.rb
require 'drb/drb'
class FactServer
def initialize(ts)
@ts = ts
end
def main_loop
loop do
tuple = @ts.take({"request"=>"fact", "range"=>Range})
value = tuple["range"].inject(1) { |a, b| a * b }
@ts.write({"answer"=>"fact", "range"=>tuple["range"], "fact"=>value})
end
end
end
ts_uri = ARGV.shift || 'druby://localhost:12345'
DRb.start_service
$ts = DRbObject.new_with_uri(ts_uri)
FactServer.new($ts).main_loop
List 8.7 ts01c2h.rb
# ts01c2h.rb
require 'drb/drb'
def fact_client(ts, a, b, n=1000)
req = []
a.step(b, n) { |head|
tail = [b, head + n - 1].min
range = (head..tail)
req.push(range)
ts.write({"request"=>"fact", "range"=>range})
}
req.inject(1) { |value, range|
tuple = ts.take({"answer"=>"fact", "range"=>range, "fact"=>Integer})
value * tuple["fact"]
}
end
ts_uri = ARGV.shift || 'druby://localhost:12345'
DRb.start_service
$ts = DRbObject.new_with_uri(ts_uri)
p fact_client($ts, 1, 20000)
8.8 moveとTupleSpaceProxy
先ほどの階乗を求める例でクライアントを異常終了させると、 処理が終了しなくなることがあります。
[ターミナル1] % ruby ts01.rb [ターミナル2] % ruby ts01sh.rb ## このプロセスを [Cntl-C] などで一度停止させる /usr/local/lib/ruby/1.8/drb/drb.rb:554:in `read': Interrupt from /usr/local/lib/ruby/1.8/drb/drb.rb:554:in `load' .... ## 再起動 [ターミナル2] % ruby ts01sh.rb [ターミナル3] % ruby ts01c2h.rb ## 終了しない‥‥
ts01sh.rbのFactServerがtakeの呼び出し中に[Ctrl-C]などで停止したのですが、 ts01.rbのTupleSpaceの中で行なわれていたtakeの処理が中断しないために タプルを紛失してしまったのです。 これはdRubyの制限によるものです。 dRubyではリモートのメソッド呼び出しにおいて、 呼び出し側のプロセスやスレッドが終了しても それをリモートに伝えることができません。 このため、呼び出し側が終了しても、リモートのメソッドの処理は 継続してしまうのです。
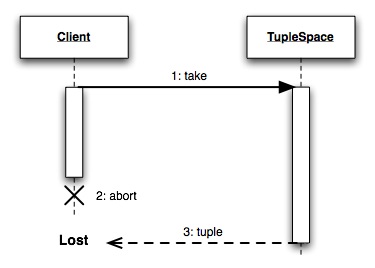
図8.10 take中の呼び出し側の中断によりタプルを紛失する例
これを回避するために、TupleSpaceにはtakeによく似たmoveメソッドが 用意されています。
move(port, pattern, sec=nil, &block)-
タプルをportへ移動させます。 takeと同様にタプルを取り出しますが、タプルをport.push(tuple)してから タプルを削除します。port.push(tuple)に失敗するとこのmoveは無効となり タプルは削除されません。これによってタプルの移動の失敗ほ捉えることが でき、タプルの紛失を防ぎます。
moveはそれ単体で使われることはあまりありません。 rinda/rinda.rbにはこのmoveメソッドを用いて安全なtakeを行なう TupleSpaceProxyクラスが定義されています。 参考にTupleSpaceProxyのtakeの定義を示します。
class TupleSpaceProxy
def take(tuple, sec=nil, &block)
port = []
@ts.move(DRbObject.new(port), tuple, sec, &block)
port[0]
end
end
TupleSpaceProxyに準備されているメソッドはほぼTupleSpaceと同じです。 TupleSpace(あるいはその参照)を与えてTupleSpaceProxyを生成したあとは、 TupleSpaceと同様に使用できます。
Rinda::TupelSpaceProxy.new(tuplespace)-
リモートのTupleSpaceを与えてTupleSpaceProxyを生成します。
ts01sh.rbをTupleSpaceProxyを用いて異常終了に対応した版を示します。
List 8.8 ts01shp.rb
# ts01shp.rb
require 'rinda/rinda'
class FactServer
def initialize(ts)
@ts = ts
end
def main_loop
loop do
tuple = @ts.take({"request"=>"fact", "range"=>Range})
value = tuple["range"].inject(1) { |a, b| a * b }
@ts.write({"answer"=>"fact", "range"=>tuple["range"], "fact"=>value})
end
end
end
ts_uri = ARGV.shift || 'druby://localhost:12345'
DRb.start_service
$ts = DRbObject.new_with_uri(ts_uri)
FactServer.new(Rinda::TupleSpaceProxy.new($ts)).main_loop
先ほどの実験と同様な手順で実行し、結果が表示されるのを確認しましょう。 (桁が多いので多少時間がかかります。)
[ターミナル1] % ruby ts01.rb [ターミナル2] % ruby ts01sh.rb ## このプロセスを [Cntl-C] などで一度停止させる /usr/local/lib/ruby/1.8/drb/drb.rb:554:in `read': Interrupt from /usr/local/lib/ruby/1.8/drb/drb.rb:554:in `load' .... ## 再起動 [ターミナル2] % ruby ts01sh.rb [ターミナル3] % ruby ts01c2h.rb 1819206320230345134827641756866458766071.........
タプルの紛失はわかりにくい不具合となります。 サブシステムの再起動や停止などが発生する場合には、 TupleSpaceProxyを生成して安全なtakeを使用するのを勧めます。
8.9 Rindaの拡張Ring
drb-2.0系のRindaから、Ringという仕掛けが追加されました。 RingはTupleSpaceを利用したネームサーバと、 ネームサーバをLANに公開する仕組みで構成されるフレームワークです。 RingのコンセプトはJavaのJiniに近いものです。
dRubyには標準的なネームサーバを用意していませんでした。 これは意図したものです。なぜ今になってRingを書いたのでしょう。 もちろん、おもしろそうだったからです。
Ringはアプリケーションがダイナミックにサービスを検索する機能を提供します。 アプリケーションはRingのネットワークに接続し自サービスをRingに登録したり、 他のサービスを検索することができます。 ダウンしたサービスを定期的にネームサーバから削除する機能や 必要なサービスが登録されたことを通知する機能を持っており、 ダイナミックにシステムのプロセス構成を変更していくことが可能です。
Ringの利点を挙げます。
- 事前にサービスのURIを知っていなくてもよい。
- 事前にネームサーバのURIを知っていなくてもよい。
- ダウンしたサービスは定期的にネームサーバから削除される。
- サービスがRingに参加した通知を受け取ることができる。
Ringは次の二つの要素から構成されます。
- TupleSpaceをLAN上で検索するための仕組み
- TupleSpaceを利用したネームサーバ
Ringにはネームサーバというクラスが存在するのではなく TupleSpaceをそのまま利用してネームサーバとしています。 検索したTupleSpaceはネームサーバ以外の用途(一般的なタプル操作)に 使用することもできます。
Ringでは二段階の検索でサービスを検索しますから、小さな処理単位で 起動されるスクリプト、たとえばCGIで起動されるスクリプトなどでは 全体の処理からに対する検索のコストが大きくなります。
Webアプリケーション間のあるいはWebアプリケーションとバックエンドのサービス間 などの長生きするプロセスでの利用に向いています。
8.9.1 Jiniにくわしい方へ (コラム?)
RingはJiniのdiscovery, lookupに似ていますが、 リースに相当する部分の考え方が異なっています。
Ringでは他のプロセスに提供されるオブジェクト一般を リースで管理するのではなく、 TupleSpaceに登録されているエントリ(タプル)に有効期限を つけるだけにとどめています。
タプルの有効期限の更新は登録したサービスの責任となりますが、 サービスに対して定期的にTupleSpaceからコールバックすることができるので、 サービス側の更新のためのコードはとても小さなものとなります。
8.9.2 ネームサーバの場所
単純なネームサーバであればHashをdRubyで公開するだけで済んでしまうため、 dRubyにはネームサーバをライブラリとして提供していませんでした。 Hashを使ったネームサーバはたとえば次のようなものです。 'druby://localhost:12345'というURIでネームサーバを準備します。
require 'drb/drb'
DRb.start_service('druby://localhost:12345', Hash.new)
DRb.thread.join
ネームサーバに'MyApp'というエントリを追加するには以下のようにします。
require 'drb/drb'
require 'myapp'
DRb.start_service(nil, MyApp.new)
ns = DRbObject.new_with_uri('druby://localhost:12345')
ns['MyApp'] = DRbObject.new(DRb.front)
DRb.thread.join
ネームサーバから'MyApp'に登録されているオブジェクトを利用するにはこのように なります。
require 'drb/drb'
DRb.start_service
ns = DRbObject.new_with_uri('druby://localhost:12345')
my_app = ns['MyApp']
my_app.do_it()
ところでこの方式にはいやなところがあります。 事前にネームサーバの場所を知っていなくてはならない、という点です。 ネームサーバ利用者もネームサーバ自身もネームサーバのURIを起動前に 知っておく必要があります。 上記の例ではスクリプトの中にURIを記述しましたが、 設定ファイルや環境変数などに記述するにしてもやはりネームサーバの URIを知らなくてはらならないことにかわりありません。
小さなシステムではネームサーバの場所を事前に教えるのであれば、 直接アプリケーションのサービスの場所を教えあっても大した手間の差は ないでしょう。
こういった点からdRubyの適用領域となりそうな小さなシステムでは ネームサーバを準備しないことにしていました。
事前にネームサーバのURIを知らなくてもよいシステムにするには どうすればよいのか、という悩みがRing開発の出発点でした。
8.9.3 TupleSpaceの検索
RingではTupleSpaceを利用してネームサーバを実現しますが、 TupleSpaceを利用する前に公開されたTupleSpaceを捜し出さなくてはなりません。 公開と検索について説明します。
TupleSpaceの公開 - RingServer
RingはUDPのブロードキャストを使ってTupleSpaceの公開/検索を行ないます。 RingServerはTupleSpaceのUDPによる公開をサポートするクラスです。 RingServerはUDPのポートを監視し、リクエストを受信するとTupleSpaceの 参照を返信します。
もっとも簡単なRingServerの使用例を示します。
List 8.9 ring00.rb
# ring00.rb require 'rinda/ring' require 'rinda/tuplespace' DRb.start_service ts = Rinda::TupleSpace.new place = Rinda::RingServer.new(ts) DRb.thread.join
RingServerを使用するには公開したいタプルスペースを与えてnewします。
RingServer.new(ts, port=7647)-
公開するタプルスペースを与えてRingServerを生成します。 RingServerはportで指定したUDPのポートを使ってタプルスペースを 公開します。ポート番号のデフォルトは7647です。
RingServerの実装はちょっとトリッキーです。 RingServerはUDPのポートにDRbObjectが届くのを待ち続けます。 UDPで実際に送信されるオブジェクトは次のようなArrayタプルです。
[:lookup_ring, DRbObject.new(block)]
受信したDRbObjectのcallメソッドを、公開するタプルスペースを与えて 呼び返します。
tuple[1].call(@ts)
UDPはDRbObjectを待ち受けるだけで返信には使用しません。 返信はDRbObjectのリモートメソッド呼び出しを用います。 検索側がUDPを待ち受けるコードを書くのがめんどうになるため、 結果はdRubyのRMIで受けとることにしました。
TupleSpaceの検索 - RingFinger
RingFingerはRingServerで公開されたタプルスペースを探す ユーティリティクラスえす。 インスタンスをつくって詳細に探す使い方と、 クラスメソッドを利用する簡単な検索の二通りの検索が可能です。
RingFingerはUDPでprocの参照(=DRbObject)をブロードキャストして、 RingerServerにコールバックしてもらうことでRingServerを検索します。
RingServerを一つだけ探すには RingFinger.primary を、 ネットワーク上の全てのRingServerを探すにはRingFinger.to_aを用います。 RingFingerの使用に先だって、dRubyのサービスを起動しておく必要があります。 RingServerを一つだけ探すには次のようにします。
require 'rinda/ring' DRb.start_service ts = RingFinger.primay
RingFinger.finger-
RingFingerの代表的なインスタンスを返します。はじめて呼ばれたとき、 lookup_ringでRingServerを検索します。
RingFinger.primay-
RingFinger.fingerによって最初に見つけたRingServerのTupleSpaceへの 参照を返します。
RingFinger.to_a-
RingFinger.fingerによって見つけた全てのTupleSpaceの参照を返します。
RingFingerのインスタンスを生成して、より詳細に検索することもできます。
RingFinger.new(broadcast_list=['<broadcast>', 'localhost'], port=7647)-
RingFingerを生成します。ブロードキャストの範囲とポート番号を指定できます。
lookup_ring(timeout=5, &block)-
UDPで検索パケットをブロードキャストしたあと、timeoutで指定した秒数の間 RingServerからのコールバックを待ちます。 RingServerはlookup_ringに与えたブロックに対してTupleSpaceの参照を 与えてyieldします。ブロックでタプルスペースを見つけるたびに行なう処理を 記述するとよいでしょう。
lookup_ring_any(timeout=5)-
lookup_ringの簡易版で最初にコールバックしてきたRingServerの タプルスペースを返します。 timeout秒の間に一つも見つからない場合にはRingNotFound例外があがります。
RingFingerのインスタンスによる検索は、ブロードキャストの範囲などを こまかく指定することができます。RingFingerのクラスメソッドによる検索は、 最初の検索結果をキャッシュするので要求ごとに検索することがありません。 状況によって使い分けてください。 簡単なアプリケーションではクラスメソッド版の検索で充分と思われます。
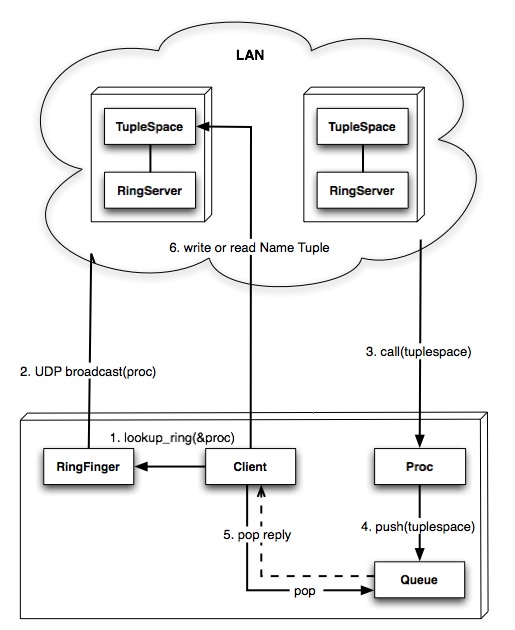
図8.11 RingFingerによる検索の仕組み - RingFingerのlookup_ring_anyの様子
細かいことですが、RingFingerのクラスメソッドによる検索は シングルトンのようなものですが、インスタンスを一つしか作らない しかけは導入していません。 「ただ一つのインスタンス」に限定する必要がないので厳密な シングルトンとする必要がないためです。
8.9.4 TupleSpaceを利用したネームサーバ
RingではTupleSpaceを用いてネームサーバを実現しています。 といっても、ネームサーバ用のTupleSpaceを用意しているわけではなく、 RingServer/RingFingerで公開したタプルスペースをそのまま使います。
Ringのネームサーバは次のようなアイデアで実現されます。
- オブジェクトの名前、種類、参照をタプルにする
- タプルをTupleSpaceにwriteしてオブジェクトを公開する
- パターンマッチングを用い、read/allで検索する
オブジェクトの名前を表すタプルは次の形式です。
[:name, 分類, a DRbObject, 説明文]
- tuple[0] -- Symbol。ネームサーバのエントリのタプルであることをシンボル。 値は常に:name。
- tuple[1] -- Symbol。分類を示すシンボル。たとえば :name_server、:place、:rwiki など、システム内で決めた値にすること。
- tuple[2] -- DRbObject。公開するオブジェクトへの参照
- tuple[3] -- String。エントリの説明文。どちらかと言うと人が見て使用するような 文字列で、とくに必要がなければ""やnilを与えて下さい。
具体的な使用例をみてみましょう。
# 600sec有効な名前の登録 ts.write([:name, :rwiki, book.front, "RWiki2 front"], 600) # 検索 tuple = ts.read([:name, :rwiki, DRbObject, nil]) rwiki = tuple[2]
オブジェクトの公開に関しては、ユーティリティクラスが用意されています。 RingProviderはオブジェクトの公開を支援するクラスで、次の責任を持ちます。 細かい制御が必要な場合にはタプルを直接操作してください。
- タプルの生成
- renewerの準備
RingProviderのメソッドを紹介します。
RingProvider.new(klass, front, desc, renewer = nil)-
[:name, klass, front, desc]というタプルとrenewerを準備します。 renewerを指定しない場合には、SimpleRenewerを生成します。
provide-
タプルスペースを検索し、 準備しておいたタプルとrenewerをタプルスペースにwriteします。
つまり、自分のアプリケーションの参照を公開するには RingProviderをnewして、provideすればよいのです。 実際のコードを見てみましょう。
List 8.10 ring01.rb
# ring01.rb
require 'rinda/ring'
class Hello
def greeting
"Hello, World."
end
end
hello = Hello.new
DRb.start_service(nil, hello)
provider = Rinda::RingProvider.new(:Hello, DRbObject.new(hello), 'Hello')
provider.provide
DRb.thread.join
このサンプルスクリプトでは後半の数行がミソです。 Rinda::RingProviderを生成し、provideメソッドでネットワークにオブジェクトを 公開しています。newのパラメータは前から順に公開するオブジェクトの種類、 オブジェクトへの参照、そしてオブジェクトの説明文です。
provider = Rinda::RingProvider.new(:Hello, DRbObject.new(hello), 'Hello') provider.provide
provideメソッドによってネームサーバにエントリーが追加されます。 具体的には、次のようなタプルがwriteされるます。
[:name, :Hello, DRbObject.new(hello), 'Hello']
このサービスをネームサーバから検索し、利用する例は次節以降で説明します。
8.10 Ringのアプリケーション
実際にRingを利用したアプリケーションの例を示します。 はじめに簡単なサービスを用いてRingのネームサーバの使い方を説明し、 最後にWEBrick、Div、RWikiなどで構成される複雑なシステムを紹介します。
8.10.1 待ち合わせのいろいろ
前節のRingProviderの例で使用したHelloを使用してネームサーバの利用の イディオムを見ていきましょう。 もっとも簡単な検索はreadを使う検索です。
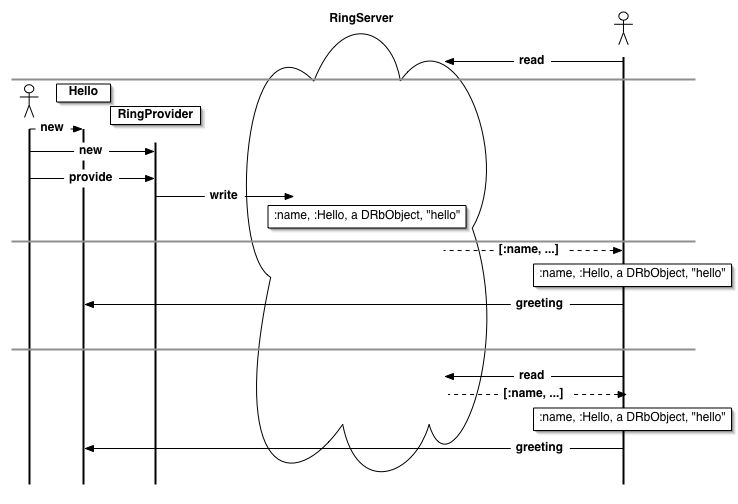
図8.12 サービスが登録されるまで、最初のreadはブロックする。二度目のreadは直ちに返る。
List 8.11 ring02.rb
# ring02.rb require 'rinda/ring' DRb.start_service ts = Rinda::RingFinger.primary tuple = ts.read([:name, :Hello, DRbObject, nil]) hello = tuple[2] puts hello.greeting
RingFingerによってタプルスペースを検索し、 パターン[:name, :Hello, DRbObject, nil]でreadします。
readで待っているので、該当するサービスが公開されるまでブロックします。 必要なサービスが準備されるまで待ち合わせることができるということです。 これはタプルスペースを使ったネームサービスの利点の一つと言えます。
実験してみましょう。最初にRingServerを起動します。
[ターミナル1] % ruby ring00.rb
次にクライアントを起動してみましょう。 まだ:Helloが登録されていないのでring02.rbはブロックします。
[ターミナル2] % ruby ring02.rb
ring01.rbを起動して:Helloを公開します。:Helloが公開されると [ターミナル2]のブロックは解除され処理が続行します。
[ターミナル3] % ruby ring01.rb [ターミナル2]続き % ruby ring02.rb Hello, World.
もう一度ring02.rbを実行してみましょう。既に:Helloが登録されていますから、 今度はただちに処理が始まります。
[ターミナル2] % ruby ring02.rb Hello, World.
待ち合わせができる点がRingのネームサービスの大きな利点ですが、 必要なサービスが準備できていない場合には、直ちに終了したい場合には タイムアウトを指定してreadするか‥
List 8.12 ring03.rb
# ring03.rb require 'rinda/ring' DRb.start_service ts = Rinda::RingFinger.primary begin tuple = ts.read([:name, :Hello, DRbObject, nil], 0) rescue Rinda::RequestExpiredError puts "Hello: not found." exit(1) end hello = tuple[2] puts hello.greeting
あるいは、read_allを用いるのも良いでしょう。
List 8.13 ring04.rb
# ring04.rb require 'rinda/ring' DRb.start_service ts = Rinda::RingFinger.primary ary = ts.read_all([:name, :Hello, DRbObject, nil]) if ary.size == 0 puts "Hello: not found." exit(1) end ary.each do |tuple| hello = tuple[2] puts hello.greeting end
read_allでは複数のエントリーを返すことがあります。 ring04.rbでは発見した全てのエントリーに対して処理をしています。 実験してみましょう。
RingServerを起動して、クライアントring04.rbを実行します。 まだHelloサービスが登録されていないので失敗します。
[ターミナル1] % ruby ring00.rb [ターミナル2] % ruby ring04.rb Hello: not found.
次にHelloサービスを二つ起動してからring04.rbを実行します。
[ターミナル3] % ruby ring01.rb [ターミナル4] % ruby ring01.rb [ターミナル2] % ruby ring04.rb Hello, World. Hello, World.
"Hello, World."が二回表示されています。 サービスが二つ登録されているので、二つのエントリに対して処理が 行なわれたためです。 もしどれか一つのサービスだけを使用すればよいのであれば、 eachで回るではなくfirstで先頭のサービスだけを取り出せばよいでしょう。
List 8.14 ring05.rb
# ring05.rb require 'rinda/ring' DRb.start_service ts = Rinda::RingFinger.primary tuple = ts.read_all([:name, :Hello, DRbObject, nil]).first if tuple.nil? puts "Hello: not found." exit(1) end hello = tuple[2] puts hello.greeting
つづいて登録されているサービスだけでなく、これから登録される サービスについても処理を行いたい場合について考えてみましょう。 先に説明したように、すでに登録されているサービスを全て取り出すには read_allが使えます。 これから登録されるサービスについてもはどうしたらよいでしょう。 readでは一つだけ待ち合わせできますが、登録されたタプルを順に 知ることはできません。 サービスの登録もタプルスペースへのwriteで実現されますから、 notifyを用いたイベント通知を用いるのが良さそうです。
すでに登録されているサービスと、これから登録されるサービスを ストリームのように一つずつ取り出すクラスRingNotifyを書いてみます。 RingNotifyは注目するサービスの種類を与えて生成し、 eachメソッドで発見したサービスを取り出します。
List 8.15 ringnotify.rb
# ringnotify.rb
require 'thread'
require 'rinda/ring'
class RingNotify
def initialize(ts, kind, desc=nil)
@queue = Queue.new
pattern = [:name, kind, DRbObject, desc]
open_stream(ts, pattern)
end
def pop
@queue.pop
end
def each
while tuple = @queue.pop
yield(tuple)
end
end
private
def open_stream(ts, pattern)
@notifier = ts.notify('write', pattern)
ts.read_all(pattern).each do |tuple|
@queue.push(tuple)
end
@writer = writer_thread
end
def writer_thread
Thread.start do
begin
@notifier.each do |event, tuple|
@queue.push(tuple)
end
rescue
@queue.push(nil)
end
end
end
end
open_streamメソッドでnotifyを行ってからread_allをしています。 read_allをしてからnotifyをしてしまうと、運悪くread_allとnotifyの 間に行われたwriteを捉え損ねることがあるため、notifyの後にread_allと しています。運悪くnotifyとread_allの間にwriteがあっても、 それを見逃すことはありませんが、二重に報告してしまうかもしれません。
ring06.rbはRingNotifyを用いて、既に登録されているサービスと 後から追加されるサービスの両方に対応したHelloサービスのクライアントです。
List 8.16 ring06.rb
# ring06.rb require 'rinda/ring' require 'ringnotify' DRb.start_service ts = Rinda::RingFinger.primary ns = RingNotify.new(ts, :Hello) ns.each do |tuple| hello = tuple[2] puts hello.greeting end
実験してみましょう。最初にRingServerを起動します。
[ターミナル1] % ruby ring00.rb
続いてHelloサービスの起動です。
[ターミナル2] % ruby ring01.rb
次にクライアントをring06.rb起動してみましょう。Helloサービスが 登録されているので"Hello, World."が直ちに印字されます。 そして次のHelloが公開されるのをブロックして待ちます。
[ターミナル3] % ruby ring06.rb Hello, World.
もう一つring01.rbを起動してHelloを公開します。
[ターミナル4] % ruby ring01.rb
Helloが公開されたので[ターミナル2]のブロックは解除され処理を行い、 再び次のHelloが公開されるのを待ちます。
[ターミナル2]続き % ruby ring06.rb Hello, World. Hello, World.
このようにread_allとnotifyを用いると、依存するサービスの起動がいつでも/ 何度発生しても対応できるスクリプトを書くことができます。 依存するサービスの起動回数や起動タイミングにしばられることがなくなり、 サービスの再登録も容易になります。 多くのサブシステムを持つような複雑なシステムでは、 起動の管理を単純なものにしてくれるでしょう。
登録したサービスが終了した場合はどうでしょう。 renewerを与えてオブジェクトを登録した場合には、無効になったエントリーは 自動的に削除されます。 しかしタプルの削除が行われるのは有効期限が過ぎても更新されなかった場合なので、 数分間は無効なタプルがタプルスペースに残ります。
実験してみましょう。
[ターミナル1] % ruby ring00.rb [ターミナル2] % ruby ring01.rb ## このプロセスを [Cntl-C] などで一度停止させる [ターミナル3] % ruby ring06.rb /usr/local/lib/ruby/1.8/drb/drb.rb:706:in `open': druby://yourhost:52180 - #<Errno::ECONNREFUSED: Connection refused - connect(2)> (DRb::DRbConnError) ....
Ringのネームサービスがほぼ自動的に無効なエントリーが削除されるとは言っても 不完全な期間があるので注意が必要です。 *6
dRubyを用いたシステム一般の悩みですが、無効なリモートオブジェクトの参照に 対してできることはアプリケーションごとに様々です。 今回はメソッド呼び出しに失敗した場合には無視する、という作戦で回避してみます。
List 8.17 ring07.rb
# ring07.rb
require 'rinda/ring'
require 'ringnotify'
DRb.start_service
ts = Rinda::RingFinger.primary
ns = RingNotify.new(ts, :Hello)
ns.each do |tuple|
hello = tuple[2]
begin
puts hello.greeting
rescue
end
end
ここでは、簡単なサービスを使ってサービスの登録と検索について 以下のようなイディオムを見てきました。
- readを用いたサービスの待ち合わせ
- タイムアウト、あるいはread_allを用いたサービスの検索
- read_allを用いた複数サービスへの対応
- read_allのnotifyを組み合わせたサービスの再登録への対応
- サービスの終了についての議論
続いて、実際に運用している複雑なシステムのサブセットを紹介します。
8.10.2 tiny I like Ruby.
dRubyやRindaの配布元となったサイト、 I like Ruby.(http://www.druby.org/ilikeruby)は Ringを使った最初の実用的なシステムによってメンテナンスされています。 dRubyを使ったRWikiによってコンテンツの本文を作成し、 Divのアプリケーションによって整形してインデックス等を付け加えます。 また複数のDivのサンプルアプリケーションのデモも行っています。
たとえば次のサービスが起動されています。
- WEBrickによるHTTPサーバにDivのセッション管理機構Tofuを載せたプロセス。
- RWiki --- dRubyを用いたWikiサーバ
- RWiki編集Div
- RWiki整形確認Div
- パズルHako(箱入り娘)Div
- Saifu(PostgreSQLを用いた簡単なアプリケーション)Div
- ...
WEBrickによるHTTPサーバを中心に複数のDivアプリケーションが動作します。 Divアプリケーションの一部はWEBrick以外のサービス、例えばRWikiなどを 利用します。
この節では上記のうちのいくつかのサービスを説明していきます。
tofu-runner
WEBrickはRubyで書かれたTCP/IPのサーバを記述するフレームワークで、 HTTPサーバを簡単に記述することができます。 tofu-runnerはWEBrickにDivのセッション管理機構であるTofuを載せるための 簡単なサービスです。 WEBrick::HTTPServerを起動した後、TofuletFrontというHTTPServerをラップする オブジェクトを生成してこれを:Tofuletという名前で公開します。 TofuletFrontにはmount_tofuletというメソッドだけが用意されていて、 それぞれのDivアプリケーションは、:Tofuletを検索して 自身をマウントポイント(パス)にマウントします。
List 8.18 ring10.rb
# ring10.rb
require 'webrick'
require 'tofu/tofulet'
require 'rinda/ring'
class TofuletFront
include DRbUndumped
def initialize(webrick)
@webrick = webrick
end
def mount_tofulet(point, bartender)
@webrick.unmount(point)
@webrick.mount(point, WEBrick::Tofulet, bartender)
end
alias mount mount_tofulet
end
def main
DRb.start_service
logger = WEBrick::Log::new($stderr, WEBrick::Log::DEBUG)
s = WEBrick::HTTPServer.new(:Port => 2000,
:AddressFamily => Socket::AF_INET,
:BindAddress => ENV['HOSTNAME'],
:Logger => logger)
front = TofuletFront.new(s)
provider = Rinda::RingProvider.new(:Tofulet, front, 'tofu-runner')
provider.provide
trap("INT"){ s.shutdown }
s.start
end
main
RingServer(ring00.rbなど)が起動されているネットワークでring10.rbを起動すると、 起動したマシンのポート番号2000でHTTPのサービスが開始されます。
[ターミナル1] % ruby ring00.rb [ターミナル2] % ruby ring10.rb [2004-05-09 23:03:12] INFO WEBrick 1.3.1 [2004-05-09 23:03:12] INFO ruby 1.8.1 (2004-05-02) [powerpc-darwin] [2004-05-09 23:03:12] DEBUG TCPServer.new(::, 2000) [2004-05-09 23:03:12] DEBUG TCPServer.new(0.0.0.0, 2000) ....
起動したマシンのWebブラウザで試すなら、http://localhost:2000 を 開いてみるとエラーページが表示されると思います。
図を入れる予定
図8.13 WEBrick/1.3.1のエラーNot Foundが表示される。
エラーページながらもHTTPサーバが動いていることが確認できましたね。
tofu-runnerは自分のサービスを公開するだけで他のサービスを待ち合わせしません。 このためRingらしいコードはRingProviderの部分のみとなります。
dCal
以前の章で作ったdCalと、この章で先ほど書いたRingNotifyを使ってこのWEBrickに dCalを載せましょう。 RingNotifyを使って、:Tofuletのサービスを見つけるたびに "/dcal"というパスでDivCalのアプリケーションが使えるようにマウントします。 マウントポイントは起動引数で変更可能です。 dCalは:Tofuletのサービスを利用しますが、自身のサービスを公開することは ありません。
List 8.19 ring11.rb
# ring11.rb
require 'rinda/ring'
require 'divcal'
require 'ringnotify'
point = ARGV.shift || '/dcal'
DRb.start_service
bartender = Tofu::Bartender.new(DivCal::DivCalSession)
notifier = RingNotify.new(Rinda::RingFinger.primary, :Tofulet)
notifier.each do |tuple|
tofulet = tuple[2]
begin
tofulet.mount(point, bartender)
rescue
end
end
fake_login.datなどのデータファイルの準備をした後に ring11.rbを起動しましょう。
[ターミナル3] % ruby ring11.rb ...
[ターミナル2]と同じマシンであれば http://localhost:2000/dcal/ を開いてみて ください。他のマシンのブラウザからの実験ではURLのホスト名を適切に設定して 試してください。dCalのLogin画面が表示されたでしょうか。
[ターミナル2]、[ターミナル3]のプロセスを停止させたり再起動させたりしながら どのように動作するか試してみてください。両方のプロセスが動作していれば、 http://localhost:2000/dcal/ は正しくdCalの画面を表示してくれることと思います。
サービスを提供する側、利用する側がそれぞれ独立して再起動しても うまい具合に復帰するのがわかります。 I like Rubyをメンテナンスする筆者のシステムは こういった仕掛けの上に成り立っています。 サブシステムの一部を簡単に再起動することができるので ちょっとしたバージョンアップや不具合の修正が容易に行えます。
とても長いRindaとRingの説明でした。ぜひあなたのアプリケーションで 使用してみてください。
*1Cを拡張したLindaはC-Lindaと呼ばれます。
*2不思議に思ってほしいところです。
*3Rinda::TupleSpaceの実装は、タプル群を線形に探索するので
おそらくスケーラビリティに問題があります。
*4かっこいいのです
*5あれ?紹介していないかも
*6仮に完全な制御ができたとしても、検索して取り出した後にサービスが終了することもあり得りえるので結局は注意が必要です。